转载自 https://www.scrapingbee.com/blog/selenium-python/ By Kevin Sahin 27 January 2020
翻译 ismdeep

在上一教程中,我们了解了如何利用 Scrapy 框架解决许多常见的网络爬虫问题。今天我们将通过教程来逐步学习 Selenium ( 使用 Python ❤️ )。
Selenium 是指用于浏览器自动化的许多不同的开源项目。它支持所有主流编程语言,包括我们最喜欢的语言:Python .
Selenium API 使用 WebDriver 协议来控制浏览器( 例如 Chrome ,Firefox 或 Safari . )。而该浏览器可以运行在本地或者是远程。
这个项目最初( 大概是 20 年前 )主要是用于跨浏览器的端到端测试( 验收测试 )。
现在它仍然用于测试,还可以用作通用的浏览器自动化平台,当然还可以用于网络爬虫。
当你必须在网站上执行下列操作时,Selenium 就特别有用:
- 点击按钮
- 填写表单
- 页面滚动
- 截屏
Selenium 对于执行 Javascript 代码也非常有用。假设你要爬取一个单页程序,而找不到直接调用底层 API 的简便方法,那么 Selenium 可能正好能满足你的需要。
安装
我们将用 Chrome 来作为演示,因为请确保你的电脑上已经安装 Chrome:
- Chrome 下载页面
- Chrome 驱动下载
selenium包
如往常一样,为了安装 Selenium 包,建议你使用虚拟环境,例如通过 virtualenv 创建一个虚拟环境:
pip install selenium
快速开始
下载完 Chrome 和 Chrome驱动,并且安装了 Selenium 包之后,就可以启动浏览器了:
from selenium import webdriver
DRIVER_PATH = '/path/to/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.get('https://google.com')
以上代码会以完全模式打开 Chrome 浏览器( 跟平常用的 Chrome 浏览器一样,只是目前你的浏览器是由 Python 代码来控制的 )。你应该看到一条消息,显示现在浏览器由自动化软件控制的。
如果想要让 Chrome 浏览器运行于服务器上的无头模式( 没有任何图形用户界面 ),例如:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
driver.get("https://www.nintendo.com/")
print(driver.page_source)
driver.quit()
driver.page_source 会返回完整的页面的 HTML 代码。
这里还有另外两个有趣的 webdriver 属性:
driver.title获取页面标题driver.current_url获取当前 URL( 当网站有重定向并且你需要知道最终 URL 时,此功能就很有用了。 )
定位元素
在网站上查找数据是 Selenium 的主要用例之一。无论是用于测试套件(确保页面上存在或不存在特定元素)还是网页爬取(提取数据并将其保存以进行进一步分析)。
Selenium API 中提供了许多方法来选择页面上的元素。你可以使用:
- 标签名
- class
- id
- XPath
- CSS 选择器
我们最近发布了一篇解释 XPath 的文章,如果你不熟悉 Xpath ,建议去看看。
通常,查找元素最简单的方法就是打开你的 Chrome 开发工具并检查所需的元素。一个很酷的快捷方式就是用鼠标放在你想要突显的元素上然后按住 Ctrl + Shift + C ( macOS 则按住 cmd + shift + c )即可,这样就不必每次都右键再点击检查(inspect)。
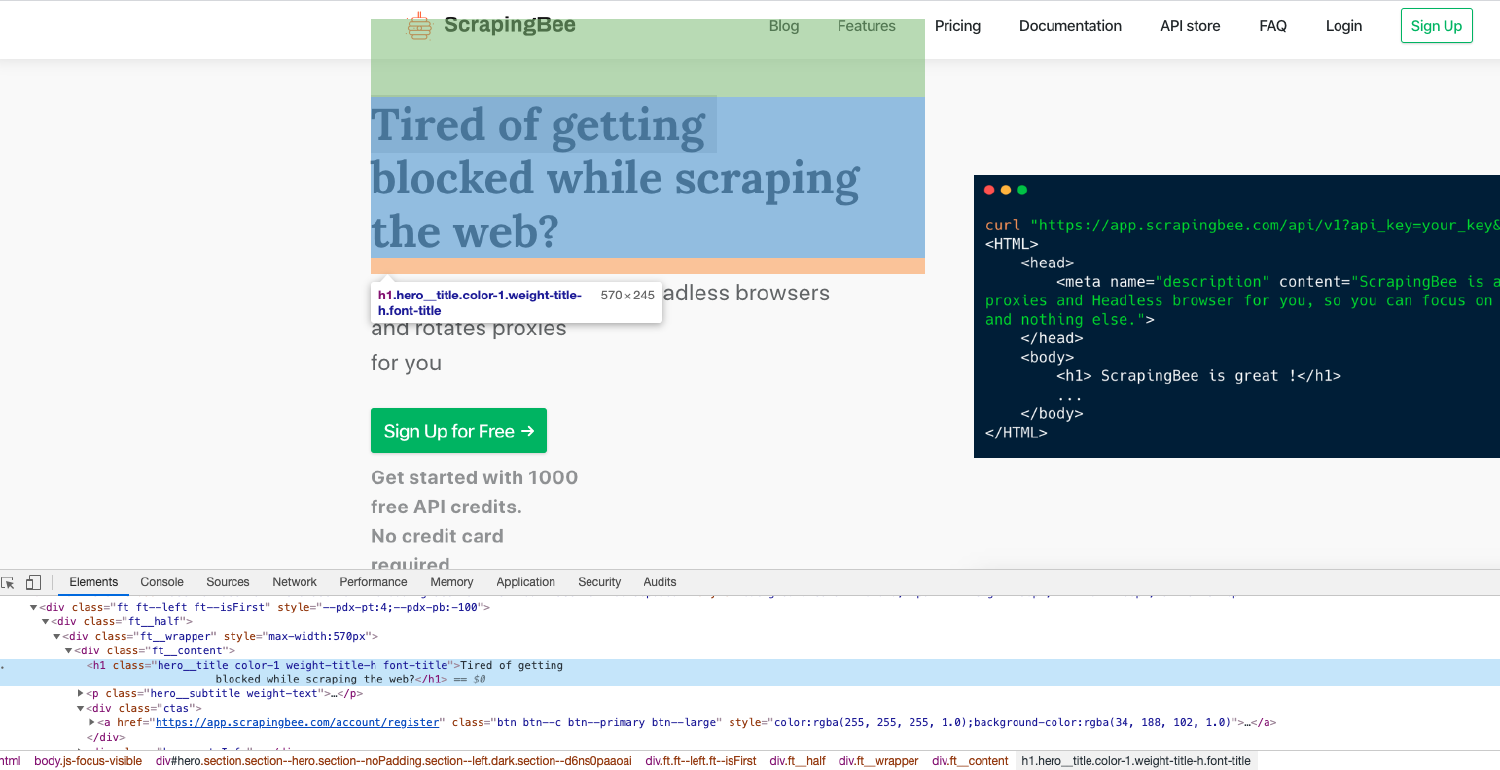
find_element
在 Selenium 中有很多中定位元素的方法。假设我们要在下面 HTML 中找到 h1 标签:
<html>
<head>
... some stuff
</head>
<body>
<h1 class="someclass" id="greatID">Super title</h1>
</body>
</html>
h1 = driver.find_element_by_name('h1')
h1 = driver.find_element_by_class_name('someclass')
h1 = driver.find_element_by_xpath('//h1')
h1 = driver.find_element_by_id('greatID')
所有这些方法都是 find_element_*() 以返回元素列表。
例如,要获取页面上的所有 a 锚点:
all_links = driver.find_elements_by_tag_name('a')
一些元素并不容易通过 id 或者 class 去获取到,这个时候你就需要 XPath 表达式来处理了。你可能还会有多个具有相同 class 的元素需要获取( id 应该是唯一的 )。
XPath 是我最喜欢用来在网页上查找元素的方式。无论是根据在页面 DOM 上的绝对位置还是相对于另一个元素的相对位置,用 XPath 来提取页面上的任何元素都是非常强大的。
WebElement
WebElement 是一个用于表示 HTML 元素的 Selenium 对象。
你可以对这些元素执行许多操作,下面是最常用的几个:
element.text可以获取到元素的文本element.click()执行对这个元素的点击element.get_attribute('class')获取属性element.send_keys('mypassword')发送文本到输入框
还有其他一些有趣的方法,例如 is_displayed(), 如果元素对用户是可见的,则返回 True .
这可以很巧妙的避免蜜罐( 例如填写隐藏的输入框 )。
完整示例
这是一个使用我们刚刚提及的有关 Selenium API 不同方法的完整示例。
我们将要登陆 Hacker News:
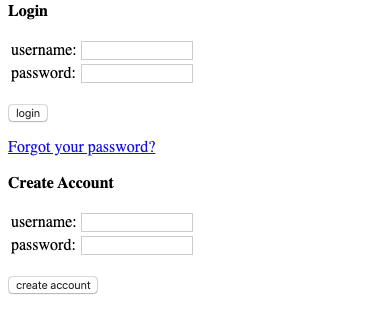
在我们的示例中,对 Hacker News 进行身份验证这件事情本身并没有真正的用处,但是可以想象我们可以创建一个自动发布指向你最新博客文章链接的机器人。
为了进行身份认证,我们需要进行以下操作:
- 通过
driver.get()打开登录页面 - 通过
driver.find_element_by_*选中用户名输入框,然后通过element.send_keys()往输入框中填入文本 - 同样的操作应用在密码输入框上
- 通过
element.click()点击登录按钮
是不是很简单?我们来看看代码:
driver.get("https://news.ycombinator.com/login")
login = driver.find_element_by_xpath("//input").send_keys(USERNAME)
password = driver.find_element_by_xpath("//input[@type='password']").send_keys(PASSWORD)
submit = driver.find_element_by_xpath("//input[@value='login']").click()
简单吧?现在,其实这里有一件很重要的事情我们没有做,那就是我们如何知道是否已经登录了?
有一下几个方法:
- 检查错误信息( 比如 “Wrong password” )
- 检查页面上只有登录后才显示的元素
我们将检查 logout 按钮,也就是 id 为 logout 的页面元素。简单!
我们并不能仅仅检查元素是否为 None ,因为所有的 find_element_by_* 函数在 DOM 中找不到元素的时候都是抛出异常。因此,我们必须使用 try/except 并捕获 NoSuchElementException 异常:
# dont forget from selenium.common.exceptions import NoSuchElementException
try:
logout_button = driver.find_element_by_id("logout")
print('Successfully logged in')
except NoSuchElementException:
print('Incorrect login/password')
截屏
通过以下代码我们就可以轻松地使用截图功能:
driver.save_screenshot('screenshot.png')
注意:使用 Selenium 截屏时,很多时候都可能会出错。首先,你必须确保窗口大小已经正确设置了。然后,你需要确保前端 Javascript 代码所进行的每一个异步 HTTP 调用均已完成,并且页面已经完全渲染显示出来。
在我们刚刚的 Hacker News 这个例子中,我们不必担心这些问题,因为这个页面非常简单。
等待元素出现
处理大量使用 Javascript 呈现内容的网站可能很棘手。如今,越来越多的网站将 Angular ,React ,Vue.js 等框架用作前端。这些前端框架处理起来很复杂,因为它们会触发许多 AJAX 调用。
如果我们不得不担心对 API 的异步 HTTP 调用(或许有很多),则有两种方法可以解决此问题:
- 截屏前使用
time.sleep(ARBITRARY_TIME) - 使用
WebDriverWait对象
如果使用 time.sleep() 则可能会使用任意值。问题在于等待的时间太长还是不够。此外,网站在本地 Wi-Fi 环境下可能加载很慢,但是在云服务器上速度则会提高 10 倍。使用 WebDriverWait 方法,你将等待加载元素或者数据的确切时间。
try:
element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.ID, "mySuperId"))
)
finally:
driver.quit()
这将等待 5 秒钟,以加载 id 为 “mySuperId” 的元素。还有许多其他有趣的条件可以使用,例如:
element_to_be_clickabletext_to_be_present_in_elementelement_to_be_clickable
你可以在 Selenium 文档 中找到有关此信息更多的信息。
执行 Javascript
有时,你可能需要在页面上执行一些 Javascript. 例如,假设你要截取一些信息的屏幕快照,但首先需要稍微滚动一下才能看到它,那么通过 Selenium 来处理就会变得轻松一点:
javaScript = "window.scrollBy(0,1000);"
driver.execute_script(javaScript)
总结
希望您喜欢这篇博客!现在你应该对 Selenium API 在 Python 中时如何工作的有了一个更好的理解。如果你想了解更多有关使用 Python 爬取网页不同的方法的信息,请随时查看我们的 python 网页爬虫指南。
对于从一些大量使用 Javascript 的网站获取数据来说,Selenium 通常是所必需的。问题是大规模运行大量 Selenium / 无头模式 Chrome 浏览器实例是很困难的。这也正是我们使用我们网页爬虫API ScrapingBee 的原因之一。
Selenium 确实是是网络上几乎所有内容自动化的一个很出色的工具。
如果你需要执行一些重复的任务,例如填写表单,检查网站上需要登录后才有的一些信息而并没有提供 API 接口。那么使用 Selenium 自动化应该是一个不错的方法。不过不要忘记这个:

喵喵怪的小枪枪、biu~~